


For some time now I have been following top influencers of AI within LinkedIn. One of them is Lex Fridman, who holds a podcast (lexfridman.com/ai) with impressive guests like Noam Chomsky or Leonard Susskind. I found by his feed that he was being interviewed by Joe Rogan.

I first heard about Joe Rogan from his interview with Elon Musk back in 2018 and I remember thinking Joe was displayed as much as Elon. In this interview with Lex I had the same feeling.
I have seen the incredible report from the people of jrefacts (jrefacts.org/joe-rogan-vs-guests) but I wanted to do the math myself and publish the code, so everyone can do the study for any interviewer and guest.
So basically I built a script in Python that automatically tag every second with Joe (red) or Elon (blue) and plot it in a timeline.
The results for the Elon Musk interview (youtube.com/watch?v=ycPr5-27vSI&t=4788s)
- Elon: 57% versus Joe: 43% of time

Just about! Let's see with the Lex Fridman interview (youtube.com/watch?v=g4OJooMbgRE&t=7624s):
- Lex: 44% versus Joe: 56% of time

I knew it!
After analyzing more examples (from episode 1434 to 1451), it turns out that the variance is quite high, as the histogram reveals:
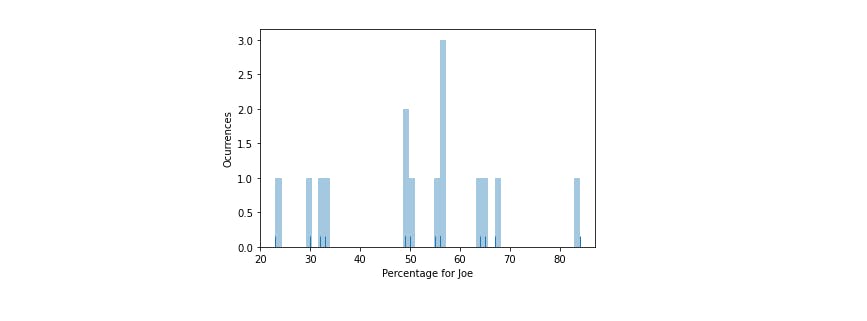
If we compute the average time for the guest, it lies around 50%, whichs seems fair for a conversation.
So no, Joe Rogan is not talking more than his guests, but the same.
Technical details
I downloaded both videos (Lex and Elon) in MP4 and opened Visual Studio Code to work a little script in Python. The idea is simple:
After a few comings and goings with facial recognition, I realized that, as the structure of the interview is fixed, we can use a simpler method like Structural Similarity Index (SSI) from scikit. So, no need of dealing with deep learning or any complicated solution. This is a simple automated annotation tool for a set of interviews with fixed scenarios.
With ffmpeg, I extracted a few snapshots (one for each "scene": both, cover, guest and rogan).

We now will be passing through the keyframes of the video (I selected one frame per second) and compute the SSI value for every reference. The winner gets it all and places its identifier in that keyframe. After computing the whole video, a numpy array is obtained with every second tagged. Now with a quick an dirty matplotlib we can produce the graphs and the stats.
You can find the script used and some results in the repository at Github (github.com/joaquincabezas/interview_meter). I will continue improving this tool so if you have a suggestion, please feel free to open an issue or contact with me directly.
Thanks for watching!